One-hot encoding
Categorical values are common in machine learning projects. For example, a student dataset may classify the students into two categories namely, ‘boys’ and ‘girls’. Similarly, a database of vehicles may classify the vehicles into four categories based on the fuel they consume -‘petrol’, ‘diesel’, ‘electric’, and ‘human powered’. However, machine learning algorithms are generally not good in dealing with textual values, and hence we have to transform them into numerical values.
The most obvious way of transforming a texttual value into a numerical value is to replace each value with a number. For example, the categories ‘petrol’, ‘diesel’, ‘electric’, and ‘human powered’ could be replaced by numbers 1, 2, 3, and 4. However, there is a catch with such simple encoding: since 4 is closer to 3 than to 1, the algorithm would be tricked to think that human powered vehicles are more similar to electric vehicles than to petrol vehicles. Such perceived connections between different categories of vehicles can potentially have a negative impact on the performance of the machine learning algorithm itself.
We can avoid this situation by replacing the categorical values by vectors. Called One-Hot Encoding, this technique replaces each categorical value by a vector containg only one 1 (hot), with rest of the elements in the vector being zeros (cold). Hence the name one-hot encoding. If there are n unique categorical values in the dataset, then there would be n elements in the vectors replacing those values. Out of those elements, only one would be 1, and the rest (n-1) would be zeroes; only the position of 1 varies from one categorical value to other.
All such vectors can be stored in a square matrix of dimension n. In that matrix, there are n 1’s, and \(n \times (n-1)\) 0’s. Since 0’s greatly outnumber 1’s, we can save a lot of space by removing all the 0’s and storing only the locations of 1’s. Such a matrix is called a sparse matrix, and that’s how Scikit-learn stores one-hot encoded values by default.
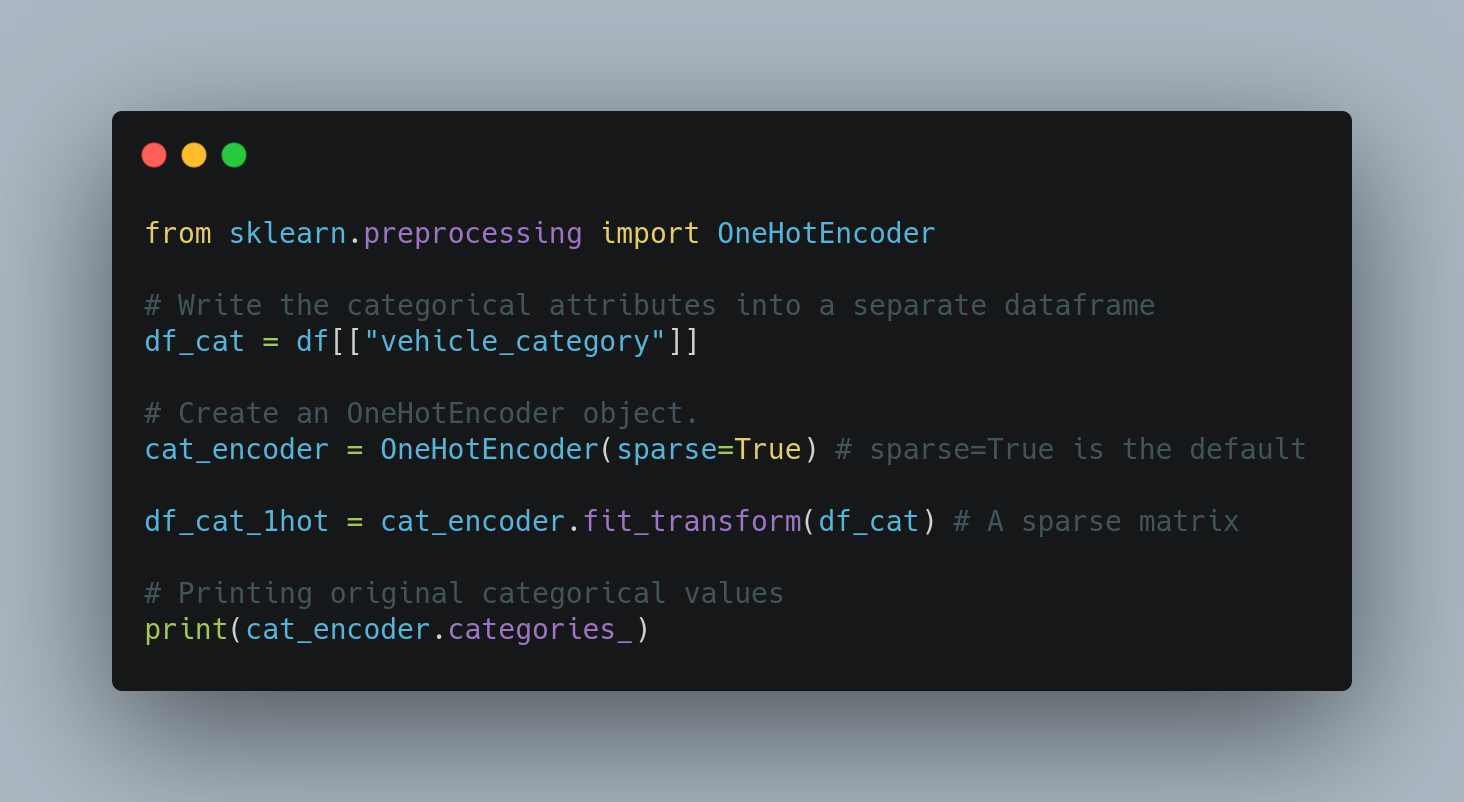
One-hot encoding in Scikit-Learn
- Create a dataframe with only the catagorical attributes. Call it
df_cat. - Import
OneHotEncoderclass and create an instance of it. While instantiating, the parametersparseis set toTrueby default. - Fit and transform the
OneHotEncoderobject. The dataframe is passed as a parameter to thefit_transform()method -
fit_transform()method returns a sparse matrix (defined in scipy). This matrix stores only the locations of 1’s, thus saving the space needed to store a large number of zeros.You can also get a matrix that stores all the 0’s in the one-hot encoded arrays. To get such a dense matrix, set
sparse=Falsewhile creating theOneHotEncoderobject. - The actual categorical values are stored in the instance variable
categories_.